阅读笔记:Zero-Change Object Tranmission (ZCOT)
背景介绍
Usenix ATC 2022 paper Zero-Change Object Transmission for Distributed Big Data Analytics 是来自上交 IPADS 实验室的一篇关于优化大数据分析中数据序列化和反序列化开销的工作。
Wikipedia 对序列化(serialization)的定义是:
1 | |
简单来说,序列化就是为了解决进程内存中的对象(object)的存储和传输问题而使用的一种手段。序列化将内存中的对象转化为某种特定格式的字节流,从而可以被存储在文件中或通过网络进行传输,而反序列化(deserialization)则是序列化的逆操作,用于将字节流重新变成内存中的对象。在分布式大数据分析的场景下,进程之间存在大量的数据传输操作,序列化和反序列化操作被频繁执行,从而演变成程序性能的瓶颈,Zero-Change Object Transmission(ZCOT)正是在这个背景下提出的。
作者从三个方面阐述了序列化和反序列化的主要缺点:
- Transformation overhead:为了将对象转化为字节流,序列化需要遍历对象中的每个成员,并将它们的类型信息和值转化成字节流,当对象复杂到一定程序时,这个操作将会非常耗时,反序列化在用字节流重构对象时,也有与序列化相当的开销。
- Memory footprint:序列化和反序列化会生成大量临时对象,从而加大内存消耗,对于存在 GC 的语言,内存消耗增加会导致频繁的进行 GC 操作,带来较大的 GC 开销。
- Duplicated transmission:序列化和反序列化以整个对象为单位,因此即便不同的对象中包含了相同的子成员,反序列化操作也不能进行复用。
在 ZCOT 之前的一些工作只针对 1 和 2 两个缺点进行了优化,而 ZCOT 则注意到了数据复用的问题,这也是这篇 paper 的一个重要的 insight。
在 ZCOT 提出之前,state-of-the-art 的优化工作有:Kyro,Skyway 和 Naos。Kryo 是一个序列化框架,相比于一般的序列化方法,Kryo 生成的数据大小更小;Skyway 可以实现直接发送 object graph(原文用了 object graph,意义同 object)而非字节流,从而消除了序列化的开销,但在易用性和引用计数的计算上存在一些缺陷;Naos 通过 RDMA 来实现对象的直接传输,也消除了序列化的开销,但依赖硬件,同时需要对现有程序进行较大修改。同时 Skyway 和 Naos 仍然无法避免反序列化。这里不再对以上工作进行展开,感兴趣的可以自行查阅相应工作的 github 或 paper。
ZCOT 与 Skyway 以及 Naos 一样,消除序列化了操作。ZCOT 仅需对现有程序进行极小的修改就能使用,也不依赖于特定的硬件,从而优于 Skyway 和 Naos,同时 ZCOT 还移除了反序列化操作和增加了数据去重。作者也从四个方面对比了 ZCOT 与其他工作,如 Figure.1 所示(其中 JSL 是 Java 内建的序列化和反序列化库):
1 | |

ZCOT 的设计
ZCOT 的设计基于 Java,可以解决不同 JVM 之间的序列化和反序列化(object serialization and deserialization, OSD) 带来的开销,如 Figure.2 所示:
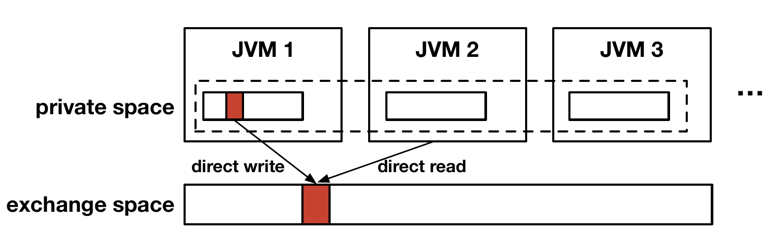
每个 JVM(Java Virtual Machine)的堆内存被分为两大部分,一部分为私有区(private space),私有区的内存与原始的 JVM 堆内存行为一致,所有对象最初产生于 private space,为当前 JVM 所独享;另一部分为交换区(exchange space),所有 JVM(包括不同 host 上的 JVM)共享这部分区域。
exchange space 的内存同样可以被 JVM 直接访问,但在内存行为上与原始的堆内存并不一致。图中展示的 exchange space 的实现并不是传统的共享内存(shared memory),而是一个类似于分布式共享内存(Distributed-Shared-
Memory, DSM)的抽象模型,可以被不同 host 上的 JVM 共享。但不同于 DSM 的是,exchange space 并不像通用的 DSM 一样需要考虑复杂的内存一致性问题等通用场景,它仅用来存储不可修改的数据。同时,为了满足程序对数据的修改需求,exchange space 实现了类似于 Copy-On-Write(COW)的机制,对 exchange space 数据的修改会导致 JVM 在 private space 创建一个数据的副本。
exchange space 的存在使得 JVM 之间直接共享数据成为可能,每个 JVM 只要对 exchange space 的内存有相同的解释,就能实现 object 的共享,从而避免进行序列化和反序列化操作。同时 ZCOT 的去重也是在 exchange space 的基础上实现的。
ZCOT 的设计主要分为三个部分:exchange space 的设计、内存管理以及数据传输的去重。以下将逐一介绍。
Exchange space 的设计
类型元数据的共享
exchange space 提供了不同 JVM 之间的数据共享机制,但对于接收者(receiver)来说,它看到的 exchange space 只是一块内存,而解释内存的元数据(metadata,包含类型信息等)则保存在 object 的发送者(sender)的内存里。如果没有这些元数据,receiver 将无法将内存解释为对应的 object。为了解决不同 JVM 对内存解释的 gap,ZCOT 提出了一种叫做 Distributed Class-Data Sharing (DCDS) 的机制。如 Figure.3 所示:
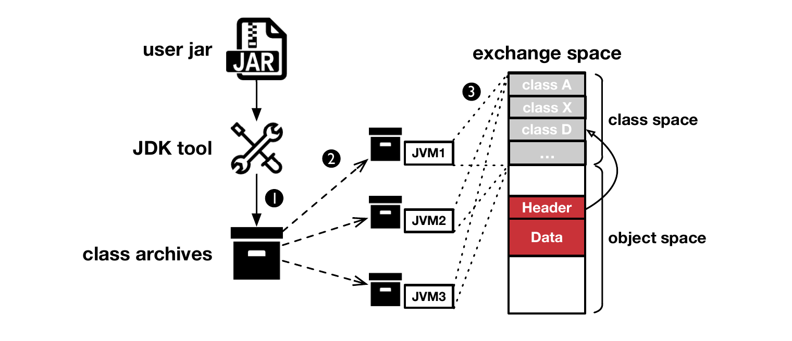
DCDS 通过 OpenJDK 提供的工具将所有 JVM 中需要共享的 object 的元数据提取出来。同时 ZCOT 将 exchange space 进一步划分为 class space 和 object space,提取出来的类型元数据会被映射到 class space 中,而共享的 object 则保存在 object space 中。object space 中每个 object 被分为 header 和 data,header 中会有一个指向类型元数据的引用,从而保证不同的 JVM 可以通过这些元数据对 exchange space 的内存拥有相同的解释,即对 exchange space 有完全相同的 view。
Object 的传输
除了保证不同的 JVM 对 exchange space 有相同的 view,ZCOT 还需要实现不同 JVM 之间的 object 传输。对此,ZCOT 设计了一个外部的 meta-server(meta-server 的实现将在后面说明)。
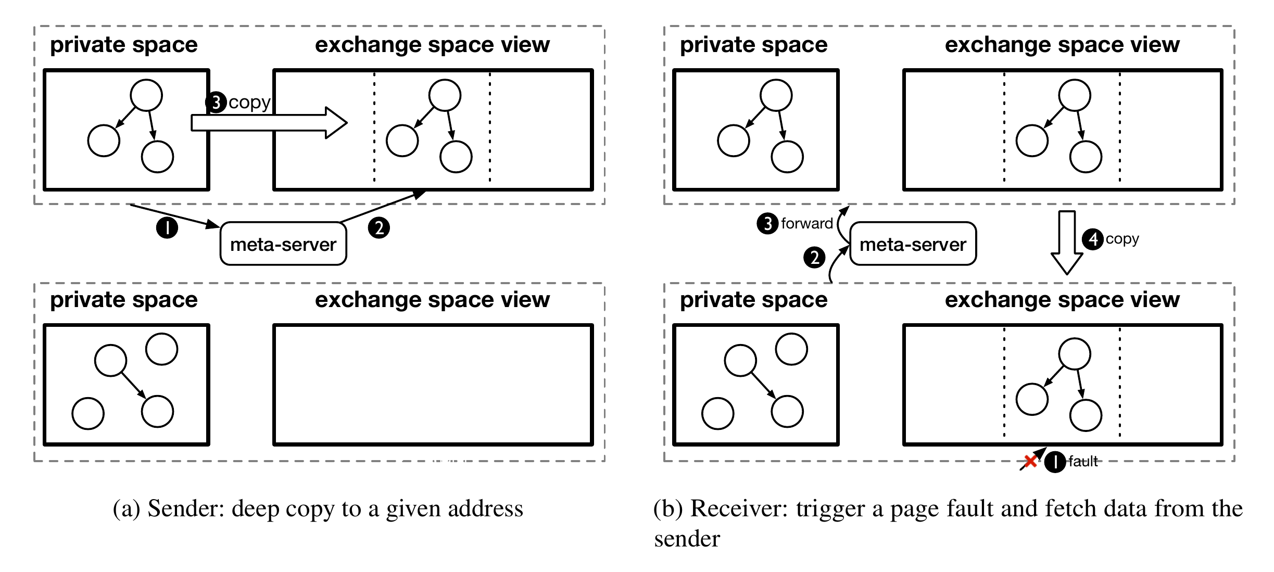
如 Figure.4 的(a)所示,对于 sender 发送 object 的情况:①sender 先向 meta-server 发送请求,请求 meta-server 在 object space 中分配一段内存用于存储该 object,②在 meta-server 找到一块可用的内存并将内存地址返回给 sender 后,③sender 将 object 深拷贝到 object space 中。此时 object 并没有被发送到其他 JVM 上,而是只保存在了 sender JVM 的内存中,只有当 receiver 请求 object 的时候,该 object 才会真正被发送到其他 JVM 中,这里采用了 lazy 机制。
如 Figure.4 的(b)所示,当 receiver 访问 exchange space 中的一个 object 的时候,如果 object 并不在当前 host 的内存中,则:①产生 page fault,②此时 JVM 会向 meta-server 请求对应的内存块,③meta-server 会根据请求找到存储该 object 的 sender JVM 的内存块,并将请求转发给 sender JVM,④sender JVM 收到请求后将与 receiver JVM 建立连接,并将 object 传输到 receiver JVM 中。这种传输仅需要将对应 object 的内存逐字节拷贝到 receiver JVM 中即可,无需进行序列化和反序列化操作,对于 receiver JVM,它可以通过 class space 中的元数据将对应内存翻译为 object。
对序列化场景的支持
exchange space 完成了将一个 JVM 中的 object 传输到另一个 JVM 的功能,因此可以替代序列化与反序列化操作,但为了将 ZCOT 应用到现有的程序中,还需要提供相应的 API。在序列化场景下,对于 sender,Java 标准库提供了 ObjectOutputStream 类的 writeObject 接口实现序列化,而 receiver 则通过 ObjectInputStream 类的 readObject 的接口将数据反序列化。为了减小修改程序的工作量,ZCOT 复用了序列化和反序列化接口。
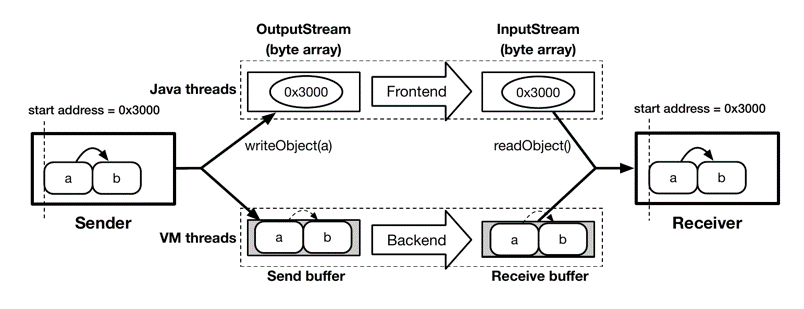
为了复用接口,ZCOT 将数据传输分为了前端和后端。如 Figure.5 所示,在前端 ZCOT 接管序列化和反序列化接口,重写了方法的实现。ZCOT 继承了 ObjectOutputStream 和 ObjectInputStream 实现了新的类,并重写了对应的 writeObject 和 readObject 方法。新的 wrteObject 方法仅对必要的元数据(包括 object 的起始地址和数据长度)进行序列化,receiver 接收到元数据后通过 readObject 获得对应 object 在 exchange space 中的起始地址和长度。
ZCOT 在前端完成了 object 的起始地址和长度的传输,但并没有将 object 的内存传输到 receiver JVM。当 receiver 访问 object 时会产生 page fault,此时由 ZCOT 后端完成剩余部分的 object 内存的传输。ZCOT 后端会创建一个新的 VM thread,并通过网络等方式将 sender JVM 的 object 内存传输到 receiver JVM 中。
此外,为了支持写入文件和网络传输,ZCOT 在新类的构建函数添加了一个新的参数 volatile,用 false 和 true 分别代表写入文件或传入网络。
对于以上设计,作者是在基于一些假设的基础上提出的:
- 所有需要进行传输 object 的类型信息(元数据)都必须能提前获取。
- 被传输的 object 需要是 read mostly。
- 所有 object 是分组(group)管理的,(同组 object?)拥有相同的生命周期。
1 | |
这些假设在大数据分析系统如 Spark 场景下是基本成立的,因此 ZCOT 适用于大数据分析系统。
1 | |
内存管理
一些语言(包括 Java、Golang 等)存在 GC 机制,由于 ZCOT exchange space 的内存行为与普通的内存并不一致,因此 ZCOT 需要对 exchange space 进行特殊处理以兼容 GC。ZCOT 对 object 的内存管理时以 group 为单位,group 即序列化场景下,一次 writeObject 所要发送的 object 的集合。在 receiver 访问数据时,page fault 总是将整个 group 的所有内存页都拷贝到 receiver 的 object space。
Metadata server
Metadata server(即 Figure.4 中的 meta-server)用于接收和处理 JVM 发来的请求,JVM 通过 RPC 的方式与 metadata server 通信,请求其分配或释放 exchange space 的内存。
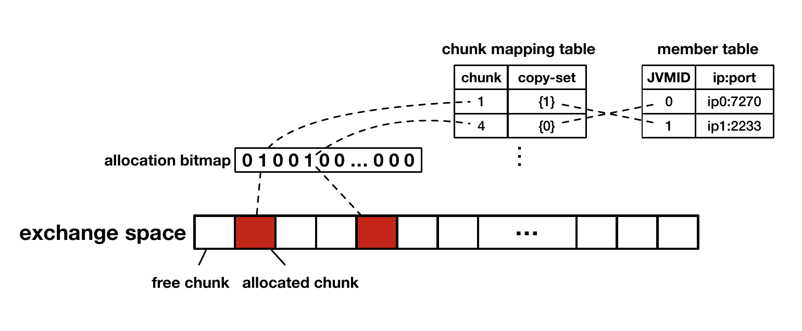
Metadata server 的内存分配以 memory chunk(256MB)为单位,并通过 bitmap 进行管理。每个 memory chunk 拥有一个序号,序号可以通过线性映射找到对应的 memory chunk 的起始地址。此外,对于每一个已分配的 memory chunck,metadata server 会维护一个 copy set,用于记录有多少个 JVM(每个 JVM 用唯一的 ID 标识)保存了这个 memory chunk 的副本,JVM 的 ID 到 JVM 的 ip 地址等信息则保存在单独的表中。如 Figure.6 所示。简单来说,metadata server 维护了 memory chunk 的分配情况,以及哪些 JVM 保存了各个 memory chunk 的副本。
此外,ZCOT 为了保证 metadata server 的可用性,引入了 metadata server 的副本(但作者并没有说明如何实现)。在通信频率较低的情况下,其开销是可接受的。
RPC 接口
ZCOT 为了实现 metadata server 的功能,设计了 4 个接口用于 JVM 和 metadata server 的通信:
int register(std::string ip, int port);Chunk* acquire();Chunk* get_remote(Address addr);int release(Chunk* chunk);
register 接口在 JVM 启动时被调用,将 IP 和端口发送给 metadata server,后者会返回一个 ID,JVM 后续的所有与 metadata server 的通信都需要附带这个 ID。
acquire 接口用于请求 metadata server 为其在 exchange space 中分配一个可用的 memory chunck,并发问题则通过锁来解决。
get_remote 接口在 JVM 发生 page fault 时被调用,metadata server 收到请求后,会找到存储地址对应的 memory chunk 的 JVM,并转发该请求,由对应的 JVM 将 object 传输到发生 page fault 的 JVM 上。由于 memory chunk 非常大,为了减少数据传输体积,JVM 只会传输需要用到的页而非整个 memory chunk。
release 接口用于释放一个 memory chunk,当申请该 memory chunk 的 JVM 和保存该 memory chunk 的 JVM 都释放了该 memory chunk 后,该 memory chunk 则会被彻底释放,并可以通过 acquire 接口再次分配。
Garbage collection(GC)
Java 的 GC 会访问所有的 object 并判断内存是否可以被回收。exchange space 在具体实现上仍然是当前 JVM 的堆内存,也会被 GC 影响,因此 ZCOT 对 OpenJDK 默认的 G1 内存回收算法进行了适配。
GC 发生时,GC 线程会暂停程序的运行,并进行内存回收或者碎片整合等操作,这里不进行展开,可以参考美团这篇文章。为了兼容 GC1 算法,ZCOT 提出了一种新的内存类型,称为 ZCRegion(每一个 group 代表一个 ZCRegion)。ZCRegion 被引用时只会被标记该 ZCRegion 被使用了,而不记录其他信息。GC 在扫描内存时,会自动跳过 ZCRegion,从而避免 object 被迁移或释放。当 GC 结束后,JVM 会扫描 ZCRegion,如果某个 ZCRegion 不存在任何引用,则调用 release 接口尝试释放该区域对应的 chunk。
1 | |
去重
ZCOT 判断一个 object 是否重复的方式是判断这个 object 是否已经存在于 exchange space。ZCOT 在将 object 拷贝到 exchange space 时,会检查对应的地址是否位于 exchange space,如果存在则对应的 object 无需再重复拷贝到 exchange space 中。
1 | |
由于去重的存在,object 之间可能存在各种依赖关系,例如 chunk A 的 object 中包含了另一个 chunk B 的 object,这就使得 chunk A 依赖于 chunk B,这会给内存的管理带来问题。为了记录依赖,ZCOT 会在 metadata server 中通过名为 dependency set 的映射表记录 chunk 之间的依赖关系。依赖的判断以及 dependency set 的更新则由 JVM 完成,JVM 判断 chunk 间存在依赖后,会通过 add_dependency 的 RPC 接口告知 metadata server。
由于依赖的存在,当 receiver 需要获取一个 object 时,需要同时获取该 object 依赖的其他 object。因此,page fault 发生时,receiver 不仅需要获取 object 自身所在的 chunk 的页,还需要读取该 object 依赖其他 object 的 chunk 的页。
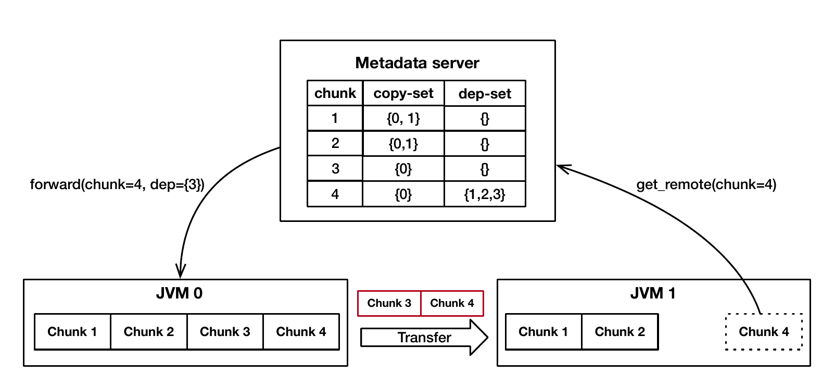
如 Figure.7 所示,JVM 1 需要获取 chunk 4 中的 object,metadata server 发现 chunk 4 依赖于 chunk 1,2,3,由于 Chunk 1,2 已经存在于 JVM 1 的内存中,因此 metadata server 只需要要求 JVM 0 将 Chunk 3,4 传输给 JVM 1 即可。
此外,ZCOT 还需要处理 GC 过程中的依赖问题。在 GC 过程中,当 JVM 检测到 ZCRegion 存在来自其他 ZCRegion 的引用时,会将当前的 ZCRegion 标记为 pinned,并将依赖关系通过 RPC 发送给 metadata server。GC 执行过程中会自动跳过被标记为 pinned 的 ZCRegion。同时当所有依赖于当前 ZCRegion 的 chunk 被释放后,metadata server 会发送一个 canRelease 的 RPC 给所有拥有该 ZCRegion 的 chunk 的 JVM,JVM 收到该 RPC 后会将对应的 ZCRegion 标记为 unpinned,从而可以被 GC 回收。
最后,ZCOT 还提供了对 internalization 的支持。Java 中对于简单类型存在 internalization 的机制,例如 - 128 到 127 的整形类会被 internalization,从而这些拥有相同的值的整形类仅会存在一份实例。ZCOT 在启动阶段从 exchange space 中分配一块内存用于存储这些被 internalization 的对象,从而实现对 internalization 的支持。
1 | |
性能评估
实验设置
作者将 ZCOT 在 OpenJDK 11.08-GA 的 HotSpot JVM 中实现了。并通过三类 workload 去评估:
- Microbenchmark:包括包含大量 2-dimension points, key-value pairs, hashmaps 和 media object 的数组
- Spark:一个数据分析引擎
- Flink:一个分布式数据处理引擎
性能评估的对比对象包括两种序列化框架 JSL 和 Kryo,以及两个 state-of-the-art 的设计 Naos 和 Skyway。
实验环境包括一个拥有 4 个节点,使用 100 Gbit/s Mellanox ConnectX-5 NICs 连接的集群,每个节点有双 Xeon E5-2650 CPU 和 128GB DRAM.
Microbenchmark
Microbenchmark 使用了 Naos 开源项目的 microperf tester。该 tester 包含了分布在两台机器上的一个 sender 和一个 receiver,通过发送不同类型 (Map, Media, Pair, Point) 的对象统计通信时间,堆的大小被设置为 16GB。结果如 Figure.8 所示:
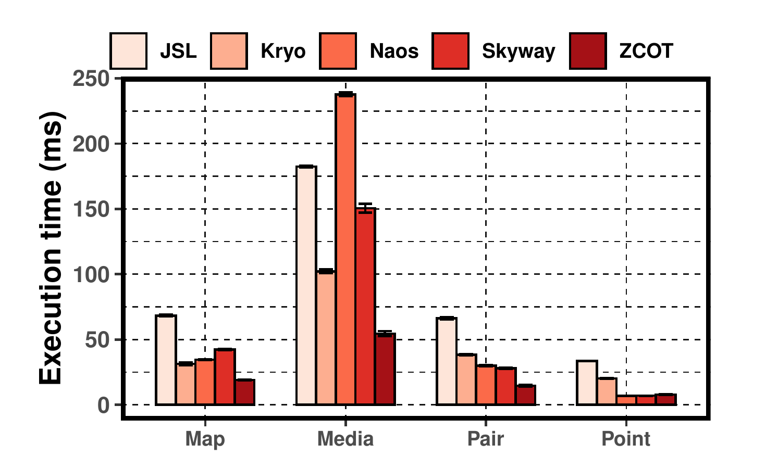
可以看出,对于 Map, Media 和 Pair 类型的 object,ZCOT 均优于其他方法,特别是 Media object 达到了最优,在这一项上 Naos 的耗时是 ZCOT 的 4.35 倍,作者对此的解释是,随着 object 的复杂度上升,在数据的计算上的开销会显著上升。对于 Point object,ZCOT 略微劣于 Naos 和 Skyway,作者的解释是 ZCOT 的性能提升被大量的网络通信带来的开销所稀释和降低了。
ZCOT 相比于 Naos, Skyway, Kryo 和 JSL 的平均速度提升分别为 2.28 倍、1.94 倍、2.19 倍和 3.95 倍。
1 | |
Spark
Spark 测试中,可能是由于作者提到的 Naos 和 Skyway 应用到现有程序的修改较大,因此作者仅比较了使用 ZCOT 与使用 Kryo 或 JSL 的性能。测试中集群的 4 个节点中的一个被用于 metadata server,而其余 3 个节点则作为 worker 进行测试,每个节点的 Heap 大小为 80GB。作者测试了 5 种应用,如 Figure.9 所示。
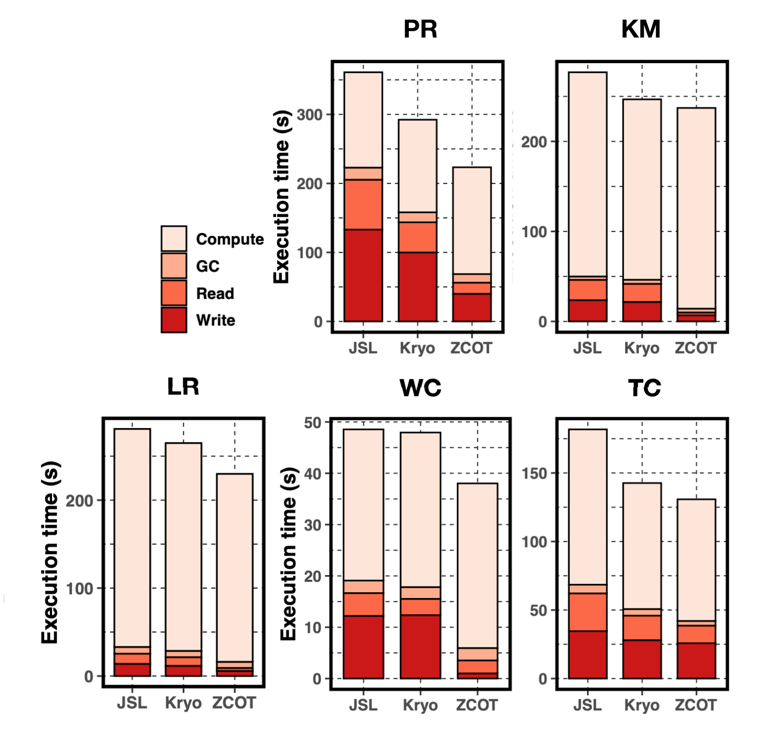
在 Spark 测试中,ZCOT 相比于 Kryo 和 JSL 的平均性能提升分别达到了 13.9% 和 24.1%。从 Figure.10 中可以看出,ZCOT 在 Read/Write 上的优化非常明显,在 Write 和 Read 部分相比于 Kryo 的速度分别提升了 4.19 倍和 2.95 倍,相比于 JSL 是 4.52 倍和 3.81 倍,但计算开销反而上升了,对此作者的解释是:①ZCOT 没有对 object 进行任何修改,导致传输的数据大小更大,在网络通信上消耗了更多的时间,这部分时间是被统计在计算时间中的;②数据去重使得数据分散在了不同的虚拟地址区间里,导致 cache miss 率提高。
1 | |
除了性能比较,作者在该项测试中还测试了去重的效果。为了表现去重的效果,作者统计了有去重和无去重所传输的平均数据量,如 Figure.11 所示:
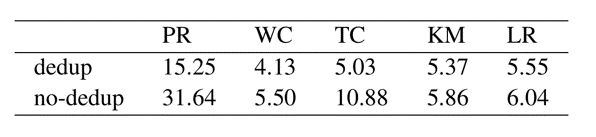
去重对数据传输量的减小从 8.1% 到 53.8% 不等,在 PR 和 TC 这两项上效果非常明显。此外,作者还基于 PR 测试项比较了不同的 Heap Size 和 Chunk Size 对 ZCOT 的影响,如 Figure.12 所示:
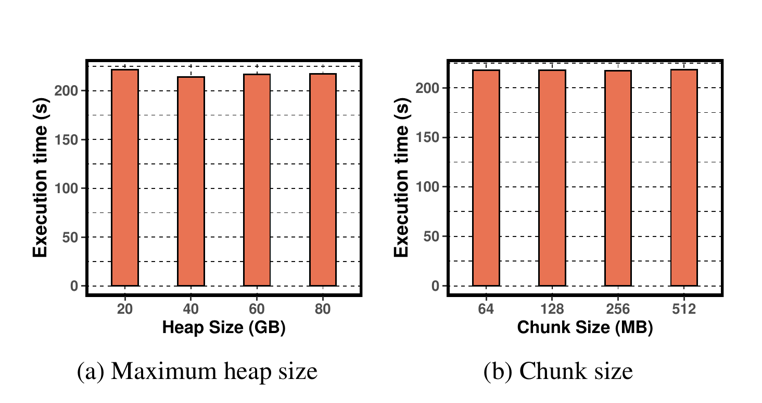
可以看出 Heap Size 和 Chunk Size 对结果的影响非常小。
最后,由于 ZCOT 在兼容 GC 时对 JVM 的 write barrier 进行了修改,因此作者也比较了修改后的 write barrier 带来的开销,相比于未修改的 write barrier 平均开销为 2.73%;同时,metadata server 的平均耗时约为几毫秒,而一次数据处理过程的耗时为以秒为单位。因此修改后的 write barrier 和 metadata server 带来的开销都可以说是极小的。
1 | |
Flink
与 Spark 测试类似,该项测试也仅比较了 ZCOT 方法与序列化框架的性能优劣,只不过使用的序列化框架是 Flink 内建的 Vanilla。测试同样把 3 个节点作为 worker,1 个节点作为 metadata server,并且每个节点的 Heap 大小为 20GB。
测试使用了 TPC-H benchmark 中 4 中具有代表性的 SQL query 语句(Q1, Q3, Q6 和 Q10)。结果如下所示:
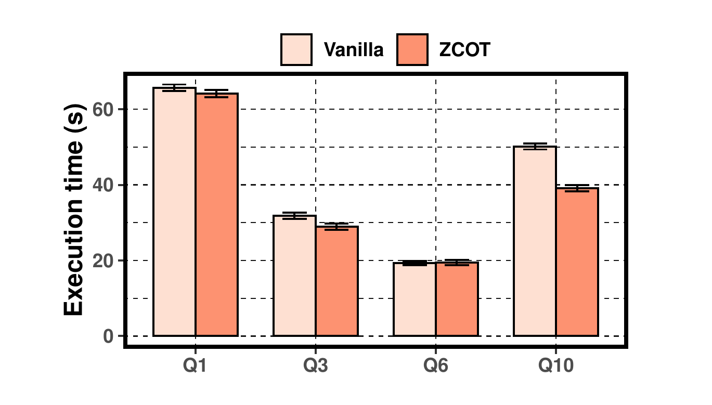
ZCOT 在 Q1, Q3 和 Q10 上的结果均优于 Vanilla,平均性能提升为 2.3% ~ 22.2%。但在 Q6 上 ZCOT 却没有任何提升,作者对此的解释是 Q6 没有进行 reduce 操作,并且传输的数据量有限。ZCOT 在 Q10 上的表现最好,对 Write 和 Read 操作的提升分别达到了 4.40 倍和 1.44 倍。此外,作者还解释了 Flink 的内建序列化操作对特定的数据结构做了手工优化,导致看起来 ZCOT 的提升不是那么明显。
结语
总的来说,ZCOT 相比于其他 state-of-the-art 的 work 在设计上的进步有两个:第一是不仅消除了序列化操作,同时也消除了反序列化操作;第二是考虑到了数据的去重。这两点使得 ZCOT 的性能显著优于其他方法。虽然作者是基于 Java 实现的 ZCOT,但在原理上并不受限于某种特定的语言,完全可以迁移到其他语言上。虽然如此,但 ZCOT 的并不支持不同语言之间的通信,而序列化方法则没有这个限制。此外,作者提出的 ZCOT 是针对于大数据的场景,因此不是那么通用,同时在实现细节上,这篇 paper 里并没有描述太多,对于这样一个复杂的系统来说,其中的数据竞争等问题一定是非常多的。